 Жесткий диск HPE MSA 2.4TB R0Q57A
Жесткий диск HPE MSA 2.4TB R0Q57A




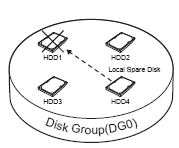
<h4>Некоторые особенности современных систем хранения данных</h4За последнее время недорогие системы хранения данных сделали довольно заметный скачок вперед по своим возможностям и производительности. К сожалению, это привело по понятным причинам к усложнениям в их настройке и применению. Задача данной заметки - популярно объяснить ряд возможностей современных массовых систем хранения данных и научить их использовать максимально правильно и без ошибок. Мы начнем с кратких описаний основных относительно новых понятий, используемых в системах хранения данных. Без понимания таких понятий остальной материал читать нет смысла. Member Disk - Диск-участник - Диск, входящий в группу дисков. Может быть как диском с данными, так и диском "горячего" резерва для данной дисковой группы. Диск с данными является частью общего дискового пространства группы дисков. Группа дисков может состоять и из одного физического диска. Disk Group (DG) - Группа дисков - под дисковой группой понимается группа из одного или несколько физических жестких дисков, на которой далее могут быть созданы логические диски. Logical Disk (LD) - логический диск - в терминологии систем хранения это диск, созданный с выделением пространства (места) на Disk Group (DG) (группе дисков). Логический диск всегда занимает непрерывное, цельное пространство в DG, которое в свою очередь всегда использует все диски группы. Довольно часто на одной дисковой группе создается один логический диск. Логический диск может быть представлен (экспортирован) во внешний мир как физический хост-компьютеру с выделением ему LUN. Logical Unit (LUN) - логическое устройство - в терминологии систем хранения представляет собой объект, к которому могут непосредственно адресоваться хост-компьютеры. LUN также должен и отрабатывать все SCSI команды, посылаемые ему хост-компьютером, так как хост-компьютер рассматривает LUN как самостоятельное физическое устройство. Local Spare - локальный резерв - в терминологии систем хранения под Local Spare подразумевается резервный, не используемый жесткий диск, который должен заменить другой жесткий диск в конкретной DG в случае выхода того из строя. После замены диска RAID контроллер автоматически восстанавливает целостность группы дисков. На рисунке ниже иллюстрируется применение Local Spare.
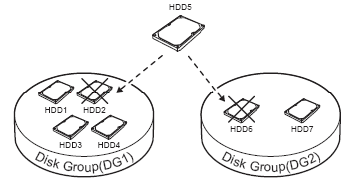
В этом примере Local Spare диск HDD4 используется для замены вышедшего из строя диска HDD1 в нулевой дисковой группе DG0 Global Spare - глобальный резерв - в терминологии систем хранения под Global Spare подразумевается резервный, не используемый жесткий диск, который должен заменить другой жесткий диск в любой DG в случае выхода того из строя. После замены RAID контроллер автоматически восстанавливает целостность группы дисков. На рисунке ниже иллюстрируется применение Global Spare.
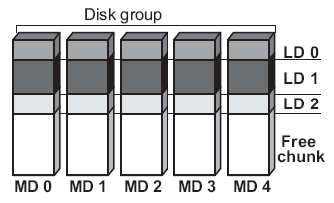
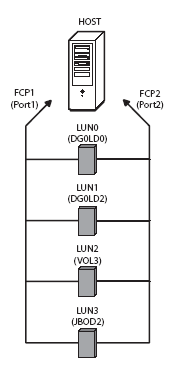
В этом примере Global Spare диск HDD5 может использоваться для замены вышедшего из строя диска HDD2 в первой дисковой группе DG1 или диска HDD6 во второй дисковой группе DG2. Если в системе есть несколько Global Spare дисков, то они используются последовательно, в порядке возрастания своего ID. Free Chunk - свободный кусок - в RAID системах под Free Chunk подразумевается свободное место, оставшееся в группе дисков (DG) после создания на ней логических дисков (LD). Free Chunk может появиться и после перестройки RAID массива. Если группа дисков (DG) создана, но ни одного логического диска еще нет, то вся группа дисков представляет собой Free Chunk. Volume - том - набор из нескольких логических дисков, расположенных внутри одной группы дисков (DG). Иными словами, в том можно включить один или более логических дисков, созданных на основе одной группы дисков с одним уровнем RAID соответственно. LUN Mapping - отображение логического устройства - несколько утрируя, мы можем утверждать, что LUN Mapping это варианты предъявления хост-компьютерам логических дисков и/или томов (volumes) из системы хранения данных. Например, создав логический диск, мы можем присвоить ему LUN и далее сделать его видимым только для конкретного хост-компьютера и/или конкретного канала системы хранения данных. Delayed Write Operation - отложенная запись - некоторые RAID контроллеры умеют отвечать хост-компьютеру, что операция записи завершена, хотя на самом деле данные только записались в кэш память RAID контроллера. В этом случае говорят, что контроллер поддерживает отложенную запись. Pre-Read Operation - предварительное чтение - некоторые RAID контроллеры умеют заранее считывать данные в кэш-память, которые, возможно, потребуются хост-компьютеру в будущем. Такие контроллеры применяют Pre-Read Operation после обнаружения запросов на последовательное чтение от хост-компьютера. Tagged Queuing - очередь маркированных команд - для объяснения этого термина следует сделать небольшое отступление. Еще в протоколе SCSI было создана возможность разделения этапа запроса данных от устройства и этапа их получения. Реализован этот механизм с помощью команд. После передачи команды устройству, связь хост-компьютера с ним завершается до получения запроса на обслуживание уже от устройства, а затем система опрашивает устройство, какая же именно команда выполнена. Таким образом, можно давать задания нескольким устройствам одновременно, и несколько заданий одному устройству. При этом запросы на чтение и запись ставятся внутри устройства в очередь и исполняются конкурентно – первыми те, которые требуют меньше времени. В этом режиме каждая команда помечается (маркируется), поэтому режим и получил такое название. Количество команд, которые могут быть одновременно "выстроены" в очередь, зависит от конкретного контроллера и обычно находится в диапазоне 256-512. Disk group expansion - расширение группы дисков - механизм увеличения емкости группы дисков путем добавления новых дисков. Свободное пространство в этом случае всегда появляется в конце имеющегося дискового пространства. Logical disk expansion - расширение логического диска - механизм увеличения емкости логического диска путем присоединения свободного пространства (Free Chunk). Logical disk shrink - уменьшение логического диска - механизм уменьшения емкости логического диска путем увеличения свободного пространства (Free Chunk). При использовании этого механизма следует помнить, что в отличие от Logical disk expansion уменьшение размера логического диска может привести к потери данных. Особенности построения RAID массивов в современных системах хранения Исторически считалось и многие продолжают считать, что "RAID массив" есть понятие, жестко привязанное к конкретным дискам. Иными словами, если на трех дисках создан RAID 5, то все диски принадлежат этому и только этому RAID 5. В большинстве современных и даже продвинутых RAID контроллерах на конкретной группе дисков вы сможете создать только один столь же конкретный RAID массив. Да, конечно, вы можете разделить массив на логические с точки зрения RAID контроллера и физические с точки зрения внешнего мира диски (LUN), но при этом каждый жесткий диск в обычном RAID будет принадлежать только одному RAID массиву. В последние годы столь устоявшаяся и понятная каждому специалисту система стала меняться. Для удобства решения различных задач во многих продвинутых системах хранения привязка жесткого диска к конкретному RAID массиву отсутствует. Что это означает? Ответ прост - это означает, что на фиксированной группе физических жестких дисков вы можете создавать сколь угодно RAID массивов. На трех жестких дисках, например, вы можете создать несколько RAID 5, несколько RAID 0 и/или RAID 3. Ничего не мешает и RAID 1 иметь там же. Допустимое максимальное количество RAID массивов внутри одной группы жестких дисков зависит от конкретной реализации системы хранения и обычно не бывает меньше 32. Лучше всего структуру многораидной (термин вольный и не рассчитан на занесение в анналы) дисковой группы можно понять по рисунку ниже.
где
Мы видим, что в этом примере в дисковой группе создано три логических диска LD0, LD1 и LD2 и осталось свободное место (Free chunk). Как и было обещано, каждый логический диск может иметь свой уровень RAID. LD0, например, может быть RAID 5, LD1 - RAID0, а LD2 может быть RAID 6. У любого нормального человека, незнакомого до сих пор с подобными системами, неминуемо возникнет по крайней мере 2 вопроса. Первый: Как понимать различную избыточность у RAID разного уровня? Второй: А зачем вообще это нужно? Попытаемся ответить на оба вопроса. Как понимать различную избыточность у RAID разного уровня Пожалуй, это как раз не самый сложный вопрос применительно к многораидным дисковым группам. Поясним ответ на примере выше. Если один диск (любой, разумеется) из 5 выйдет из строя, то произойдет следующее:
Другими словами, избыточность для каждого LD будет определяться уровнем RAID логического диска вне зависимости от уровня RAID других LD. Зачем это нужно Задач, которым требуется, такое построение системы на самом деле довольно много. Приведем хотя бы пару примеров.
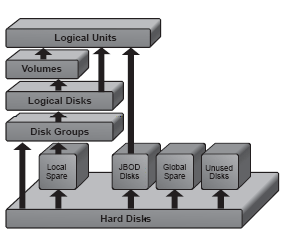
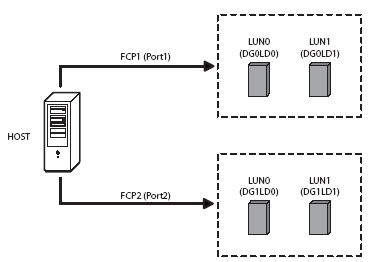
Конфигурирование системы хранения Уже зная и понимая основные понятия для систем хранения данных, мы попытаемся выяснить как именно и в какой последовательности нам следует конфигурировать современную систему хранения. Итак, в конечном итоге структура созданного нами хранилища будет приблизительно выглядеть так:
Последовательность наших действий на самом деле очень проста.
Настройка системы хранения под внешний мир Итак, мы настроили систему хранения, применив большинство настроек по умолчанию. Теперь мы познакомимся с некоторыми специфическими настройками систем хранения для правильной работы с подключенными к системе хост-компьютерами. Настройки метода использования Fibre Channel системы хранения данных Для Fibre Channel систем следует также указать системе хранения ее будущую роль (в соответствии с решаемой задачей), называемую также Storage Provisioning. Возможны, например, такие варианты: Simple method (Простой метод), Symmetric method (Симметричный метод) и Selective method (Избирательный метод). Расскажем подробнее о каждом варианте использования.
В этой таблице: OK - изменение всегда возможно. No - количество дисков. Nn - изменение возможно только при количестве дисков в новом RAID большем или равном указанному. N/A - такое изменение уровня RAID невозможно. Диагностика и обслуживание По завершении успешного конфигурирования системы хранения нам останется только следить за ней, предварительно приняв все меры к тому, чтобы исключить возможные внезапные аварии системы. Для систем с высоким требованиям к надежности мы рекомендуем использовать следующие методы и способы диагностики и обслуживания.
Настоящие заметки, безусловно, не охватывают даже большей части возможностей современных систем хранения данных - но надо же с чего-то начинать. Мы надеемся, что этот материал облегчит понимание нового поколения недорогих систем хранения данных. Мы так же надеемся на его дальнейшее развитие настоящих заметок. | |||||||||||||||||||||||||||||||||||||||||||
- ACELab
- Adaptec
- AIC
- Apacer
- Areca
- Asustor
- ATTO
- AXUS
- Broadcom
- Brocade
- BUFFALO
- Chelsio
- Cisco
- Crucial
- D-Link
- DapuStor
- Dell
- Dot Hill
- DUNE HD
- EMC
- EMULEX
- Finisar
- Fujitsu
- Hitachi
- HP
- HPE
- Huawei
- i-Stor
- IBM
- Imation
- Infortrend
- Intel
- Kingston
- KIOXIA
- Lacie
- Lenovo
- LSI logic
- Maxtronic
- Mellanox
- Micron
- Microsemi
- ORICO
- Overland
- Promise
- QLOGIC
- QNAP
- Qsan
- ReShield
- Samsung
- SanDisk
- ScaleFlux
- Seagate
- SNR
- Solarflare
- Sony
- SPATIUM
- Sun
- Synology
- TerraMaster
- Thecus
- Toshiba
- Transcend
- Turtle Case
- Western Digital
- Xyratex